

Training AI to Paint with Code

When you make an image with an AI model, the only way to participate is the prompt. You cannot edit the image directly. To change anything you go back to the model and prompt again. That limitation is what started this project. I trained a language model to make images by writing code, using reinforcement learning. The code is the artefact, and the code is editable. You can change what the model produced more granularly without going to prompt.
The deeper question this project asks is how to do reinforcement learning on creative and design tasks. RL works when the reward is verifiable. A math problem is right or wrong. A game is won or lost. Aesthetic quality is neither. The design problem moves to the reward function and the criteria a judge is asked to apply. Too rigid, and the model converges. Too loose, and the model drifts.
[Video of my thesis presentation, for the context behind this project.]
My contributions
Design
Development
RL Research
The team
Surya
Cameron Franz
Alex Wang
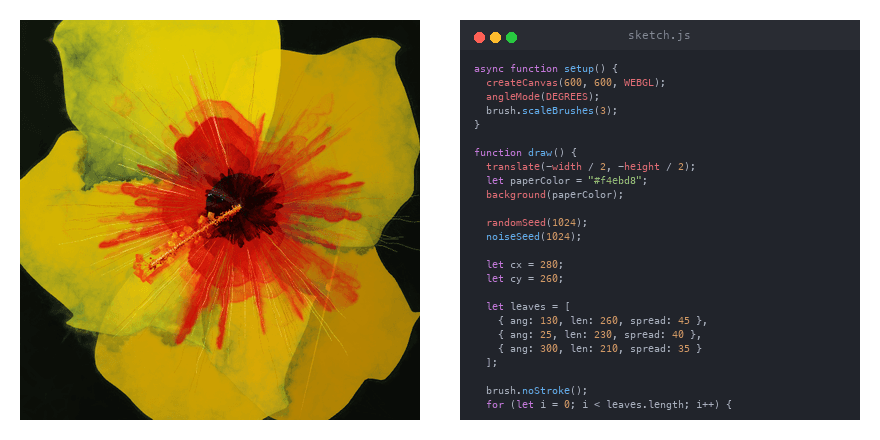
How it works
The system is a four-step loop, run thousands of times during training.
The model receives a prompt, something like draw a peach hibiscus in watercolour, and writes a complete p5.brush JavaScript sketch. The sketch is rendered in a sandboxed Puppeteer environment, which produces a PNG. The PNG is judged against two random reference paintings sampled from a hand-rated pool, with a separate judge model picking the better watercolour. The judgment is converted into a reward signal, GRPO updates the model, and the loop runs again.
The non-obvious choices live in what is being judged, how the judgment is made, what is in the reference pool, and how the system prompt is written. Each is the subject of a section below.
The training loop.
Reward Functions
Old rubric vs new rubric, reward curves on the same axes.
The reference pool
The pool has 581 reference paintings. all of which were hand rated from 1664 generations into 117 love-tier, 266 are okay, and 198 are supplements from a separate generation run used to widen the comparison set in colours where hand-rated examples were thin.
Every image in the pool is model output. As we could not source enough human made examples since the library is a niche tool artists use. The generation work ran through two pipelines. AutoResearch, with Opus 4.6, GPT-5.4, and Gemini 3.1 Pro iterating against reference photographs under a VLM judge giving scores and feedback. And a larger batch run on Gemini 3.1 Pro. Both pipelines fed a system prompt that had itself been evolved through GEPA, covered in the next section.

System prompt evolution
The system prompt also needed work. Early versions included a 400-line p5.brush API reference. The model produced confident, well-formatted code that invented APIs that did not exist.
The fix was done using GEPA, a prompt-optimisation library that evolves a prompt against a scoring function. We ran 200 iterations against a taste-anchored 7-shot judge. The optimisation converged on a prompt with a strict allowlist of eight brush methods, no API documentation, no examples. The first time three out of three generations produced visible hibiscus blobs was on the version written after throwing the 400-line reference out entirely.
The findings generalised. Long reference documentation in a system prompt made the models hallucinate APIs. A short, opinionated allowlist constrains output better than the original spec.
GEPA process diagram.
Progression
Model's output across training steps.

A selection of generations from the trained model. Each was produced by the model writing JavaScript that renders into the image.

Closing
Reinforcement learning needs a verifiable reward. A math problem is right or wrong. A game is won or lost. Aesthetic preference is neither. To do RL on subjective work, you have to author the reward by hand, and then design it carefully enough that it generalises. Too specific, and the model only learns to copy the examples you rated. Too loose, and it learns nothing in particular. RL for creative tasks is a design problem for creating structure that lets taste generalise to users preferences.
I don't think this is a better way to make images. It is, in fact, much slower. But when I started this project I was frustrated that the only way to participate in image creation with AI was through the prompt. This project let me put attention and effort across the prompt, the model, and the artefact. The project is ongoing, with one final training run aimed at fixing the issues we discovered along the way. A full technical report will be published in June 26.

